left join
磁盘已满
分布式
节点度
测试工程师
Nanoprobes
ACL
相机参数
系统错误
医学
transformers
visualstudio
统一认证
ACK
动态库
kernel
SpringBoot项目的创建
比较运算符
Conditional注解
飞机游戏
数据倾斜
2024/4/12 23:47:20
Spark数据倾斜解决方案三:随机key双重聚合
什么是随机key双重聚合
随机Key双重聚合是指Spark分布式计算对RDD调用reduceByKey等聚合类Shuffle算子进行计算,使用对Key值随机数前缀的处理技巧,对Key值进行二次聚合。 第一次聚合(局部聚合):对每个Key值加上一个随机数,执行第一次reduceByKey聚合操作。第二次聚合(双…
Spark数据倾斜解决方案六:随机前缀和扩容Join
如何扩容
两个RDD数据都特别多且倾斜的Key有成千上万个,该如何解决数据倾斜的问题?初步的想法:在倾斜的Key上加上随机数。该想法的原因:Shuffle的时候把Key的数据可以分到不同的Task里。加随机数有一个前提:必须知道哪些是倾斜的Key。但是,现在的倾斜的Key非常多,成千上…

hive优化大全(hive的优化这一篇就够了)
文章目录写在前面一、概述1.1 数据倾斜1.2 MapReduce二、产生原因三、解决方案和避免方案3.1 Hive语句初始化配置3.1.1 join过程的配置3.1.2 map join过程的设置3.1.3 combiner过程3.1.4 group by 过程3.1.5 map 或者reduce 过程3.1.6 mapper 设置3.1.7 reducer设置3.1.8 存储与…
Spark数据倾斜解决方案二:提高Reducer端的并行度
前言
提高reducer端并行度操作起来并不难,这里把它当做一个单独的方案,原因是:现在的spark程序,我们一般刚开始主要考虑的业务,对于代码写的是否忽略的性能的问题很多时候可能并不是项目一开始要考虑的事情。只有当代码经过测试的时候,可能才发现由于数据倾斜造成某个ta…
Spark数据倾斜场景及解决思路
文章目录 数据倾斜发生时的现象数据倾斜发生的原理如何定位导致数据倾斜的代码某个 task 执行特别慢的情况某个 task 莫名其妙内存溢出的情况 数据倾斜解决方案1. Hive 表中的数据本身很不均匀 -使用 Hive ETL 预处理数据2. 导致倾斜的 key 就少数几个,而且对计算本…

Hive SQL 开发指南(二)使用(DDL、DML,DQL)
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指…

数据倾斜原理及解决方案
导读
相信很多接触MapReduce的朋友对数据倾斜这四个字并不陌生,那么究竟什么是数据倾斜?又该怎样解决这种该死的情况呢? 何为数据倾斜?
在弄清什么是数据倾斜之前,我想让大家看看数据分布的概念:
正常的数据分布理论上都是倾斜的,就是我们所说的20-80原理&…
【Flink实战系列】Flink 双流 Join 出现数据倾斜如何解决?
【Flink实战系列】Flink 双流 Join 出现数据倾斜如何解决?
在 Flink 里面常见的数据倾斜有两种 计算场景Join 场景第一种计算场景,比如我们常说的 WordCount 计算,这种问题可以参考这篇文章,Flink发生数据倾斜怎么优化任务?(两段聚合的方式)
第二种 Join 场景,是我们今…
Dubbo负载均衡策略之 一致性哈希 | 京东云技术团队
本文主要讲解了一致性哈希算法的原理以及其存在的数据倾斜的问题,然后引出解决数据倾斜问题的方法,最后分析一致性哈希算法在Dubbo中的使用。通过这篇文章,可以了解到一致性哈希算法的原理以及这种算法存在的问题和解决方案。
一、负载均衡 …
各大数据组件数据倾斜的原因和解决办法
1 背景
在处理大规模数据时,数据倾斜是一个常见的问题。数据倾斜指的是在分布式环境中处理数据时,某些节点上的任务会比其他节点更加繁重,这可能导致性能下降、资源浪费等问题。数据倾斜可能会出现在不同层次的数据处理过程中,例…
分布式计算中的数据倾斜
摘要
数据倾斜是指在分布式计算中,由于数据负载不均匀或数据倾斜的特性,导致某些计算节点的负载过重,从而影响整个计算任务的性能和并行度。
数据倾斜的根本原因包括以下几个方面:
数据分布不均匀:在分布式计算中&a…
Spark数据倾斜解决方案四:Mapper端Join
为什么要在Mapper端Join
解决数据倾斜有一个技巧:把Reducer端的操作变成Mapper端的Reduce,通过这种方式不需要发生Shuffle。如果把Reducer端的操作放在Mapper端,就避免了Shuffle。避免了Shuffle,在很大程度上就化解掉了数据倾斜的问题。Spark是RDD的链式操作,DAGSchedule…
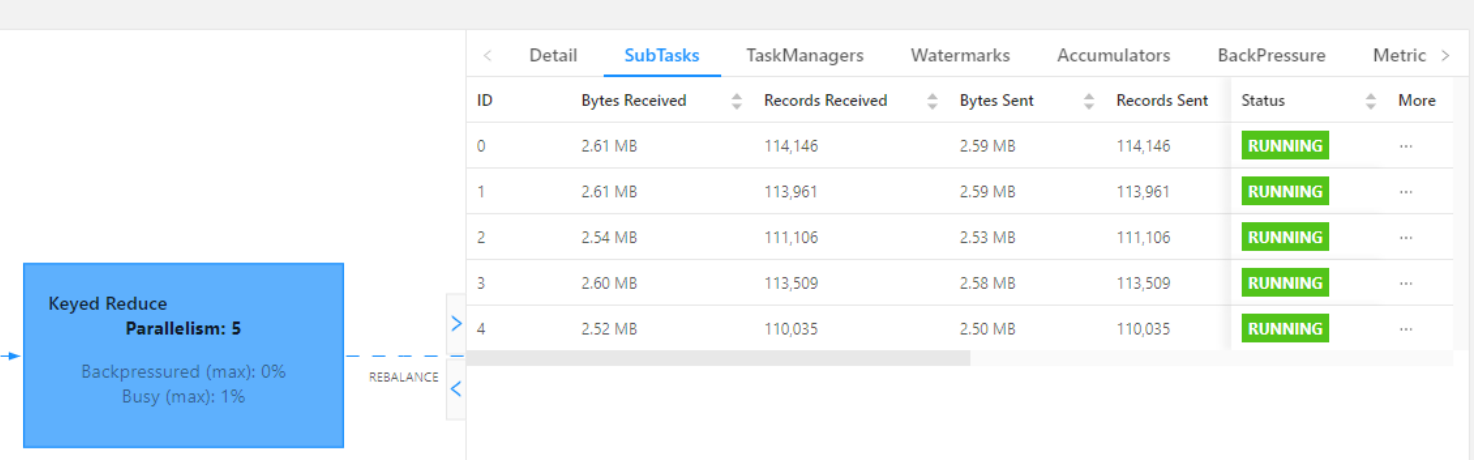
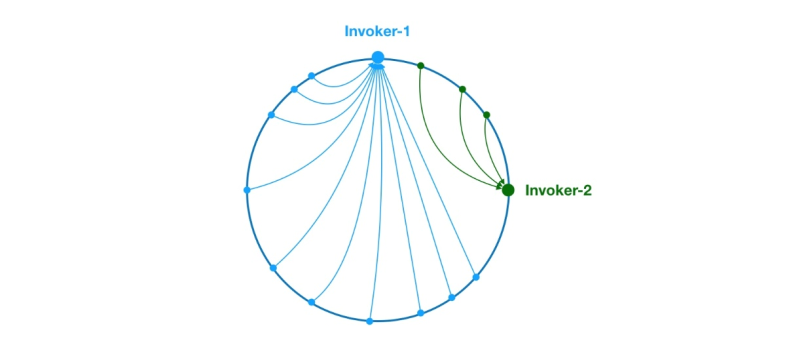
Flink流式数据倾斜
1. 流式数据倾斜
流式处理的数据倾斜和 Spark 的离线或者微批处理都是某一个 SubTask 数据过多这种数据不均匀导致的,但是因为流式处理的特性其中又有些许不同 2. 如何解决
2.1 窗口有界流倾斜 窗口操作类似Spark的微批处理,直接两阶段聚合的方式来解决…
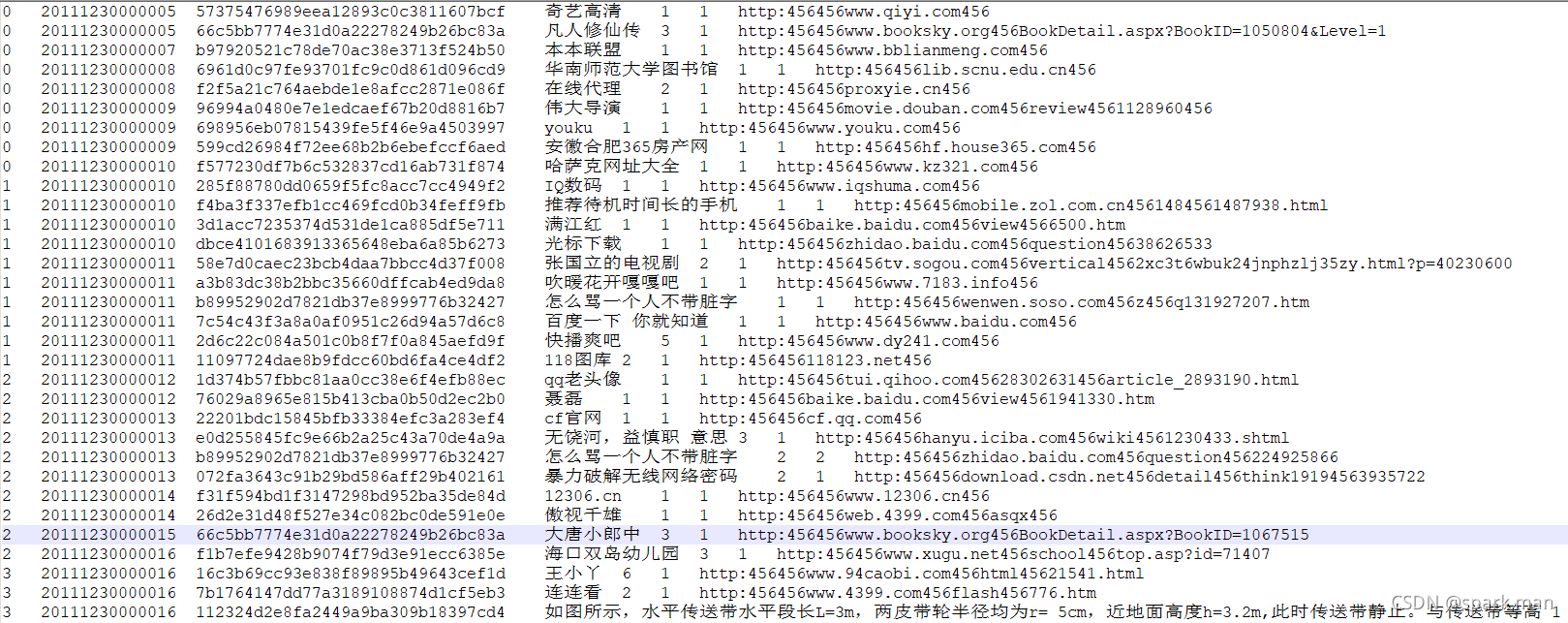
mapJoin与reduceJoin
mapreduce中可以实现map端的join以及reduce端的join,我们看下有什么区别。 mapJoin与reduceJoin数据准备reduce joinmap joinhive的map join测试数据准备
有一张订单表(order):
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6三列对应的…
Hive SQL 开发指南(三)优化及常见异常
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指…