SC 2021 Paper 分布式元数据论文阅读笔记
问题
CephFS采用动态子树分区方法,将分层命名空间划分并将子树分布到多个元数据服务器上。然而,这种方法存在严重的不平衡问题,由于其不准确的不平衡预测、对工作负载特性的忽视以及不必要/无效的迁移活动而导致性能不佳。
挑战
性能问题主要是由以下两个原因造成的:1)不准确的负载模型与忽视良性不平衡:负载监控模块未能准确模拟每个MDS的负载和集群负载,同时也不能容忍良性不平衡,其中负载不平衡水平保持在安全区间;2)无效的子树迁移候选选择:迁移决策模块不适当地选择了子树迁移候选项,没有考虑这些子树的访问模式和未来的负载变化。
现有方法局限性
Mantle [35]将负载统计收集和迁移决策步骤与CephFS的其他元数据管理分离,并提供可编程的API,允许用户指定确定何时以及迁移多少的函数。然而,这些API有限,不涵盖重要的子树选择功能。而且,得出准确的负载模型和合理的元数据迁移和负载平衡启发式仍然是一个挑战。
背景
负载均衡流程:
-
MDS节点参与收集元数据负载统计信息,以确定MDS集群是否经历了不平衡以及是否应该触发平衡。
-
将集群划分为源MDS和目标MDS,并计算出从源MDS到目标MDS之一的本地负载量。
-
每个源MDS选择一组子树或目录碎片,并将它们放入导出任务队列中,以完成计划的迁移负载,可能在需要时执行进一步的细粒度分区。
-
通过标准的两阶段提交协议,执行分区从源MDS到目标MDS的迁移。
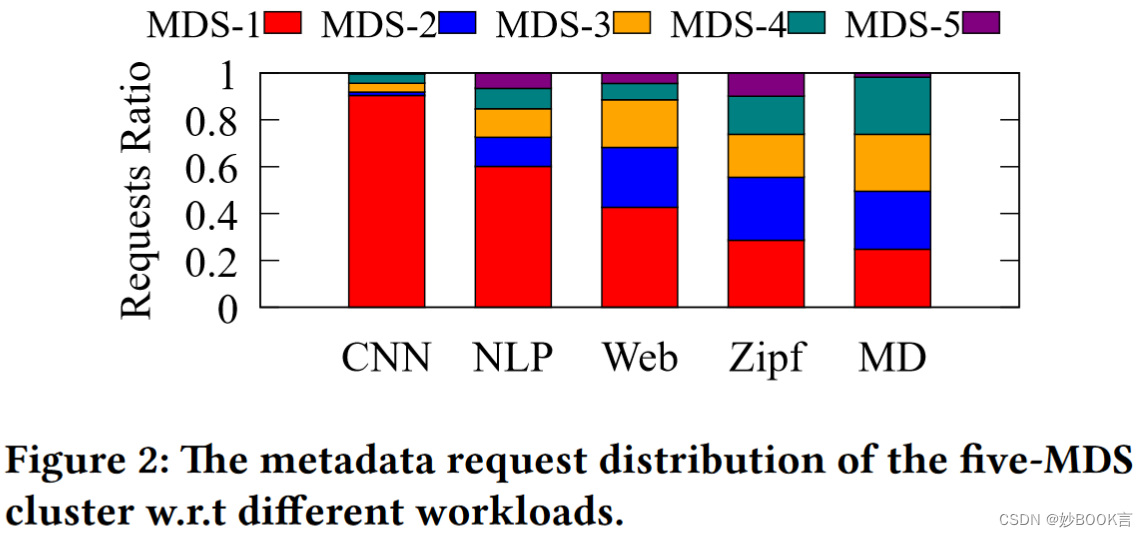
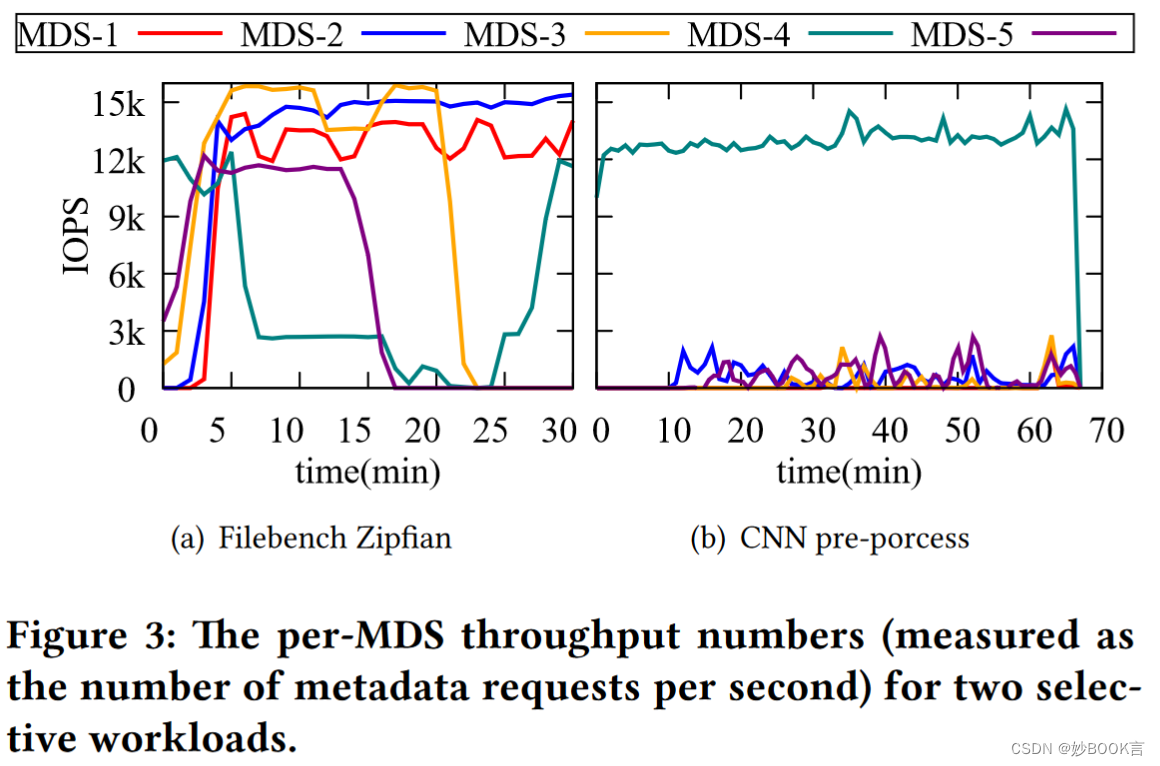
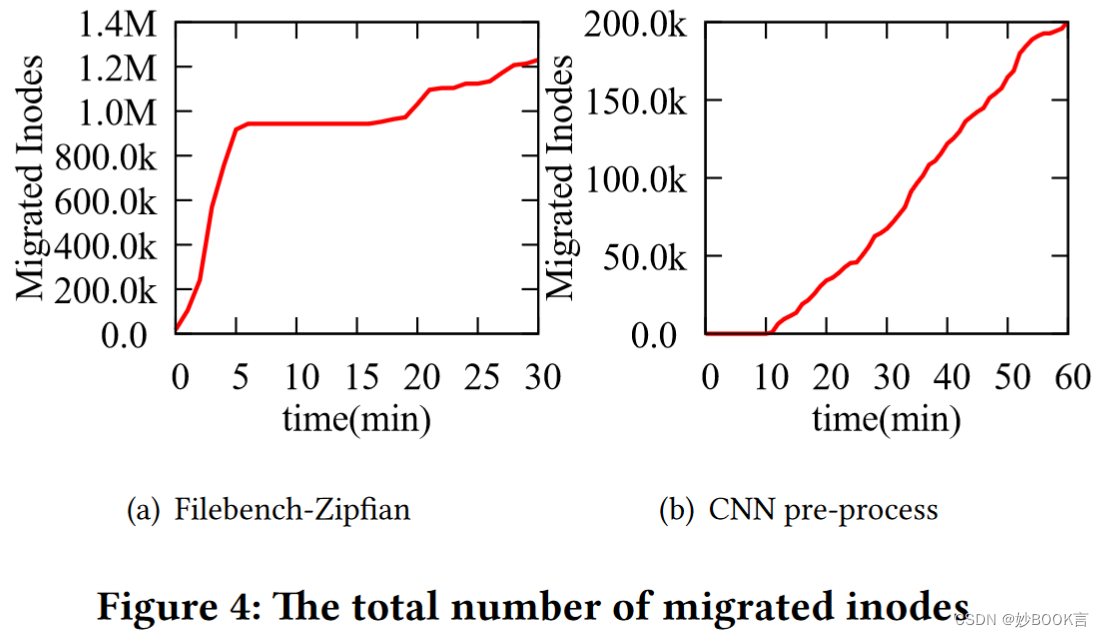
现有负载均衡算法仍存在负载不均衡问题,而且存在无效迁移:
本文方法
我们提出了Lunule,基于CephFS动态子树分区的新型元数据负载平衡器。
-
为了在需要时进行重新平衡,Lunule由一个分析模型驱动,该模型准确捕捉整个MDS集群的工作负荷强度水平。与使用平均负载统计不同,该模型使用变异系数来计算MDS集群的实时不平衡因子,以最小化噪声对迁移决策的负面影响。我们引入了一个紧急参数,用于量化不平衡情况是否对未来减少不必要的迁移安全或有害。基于该模型,Lunule确定了源MDS和目标MDS,根据MDS未来的负载变化,计算应该在两个MDS之间迁移多少数据。
-
Lunule选择在每个源MDS上要移动的子树集,准确预测不同子树的未来访问频率(分配为它们的迁移索引),并选择具有较高值的迁移子树候选是至关重要的。我们提出了一个统一的公式来估计子树过去访问活动的时间和空间局部性对其未来负载的影响。对于时间局部性,我们考虑最近的时间间隔内元数据访问的重复性,而不是依赖于当前CephFS中使用的简单累积的流行度计数器。对于空间局部性,我们考虑目标子树的元数据访问的均匀分布,并考虑兄弟子树之间的访问相关性。
开源代码:GitHub - mdbal-lunule/lunule
与基准相比,Lunule实现了更好的负载均衡,在五种真实工作负载及其混合情况下,分别将元数据吞吐量提高了高达315.8%,并将尾部作业完成时间缩短了高达64.6%。此外,Lunule能够处理元数据集群的扩展和客户端工作负载的增长,并在16个MDS的集群上呈线性扩展。
设计细节
概述
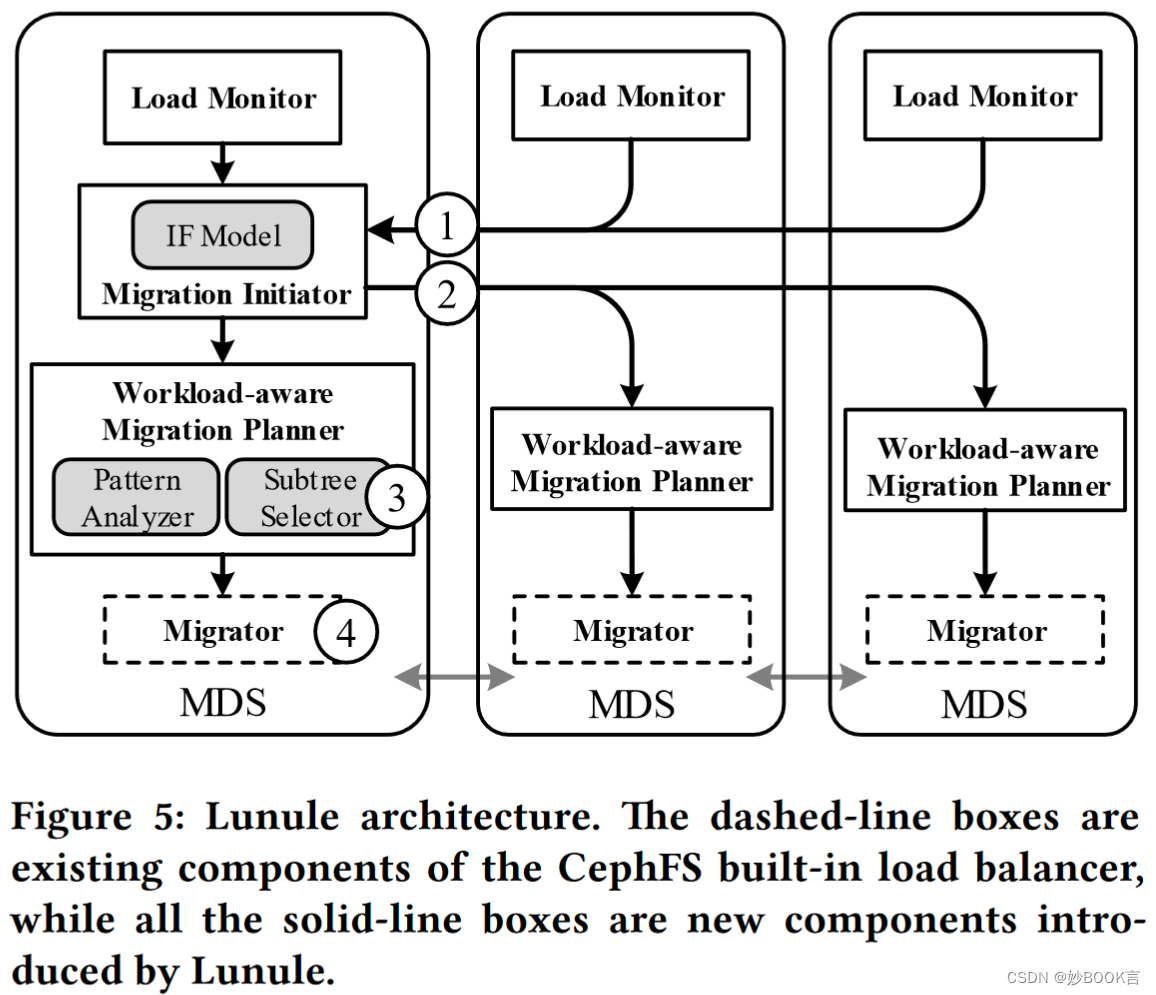
如图5所示,Lunule在称为Epoch的固定时间间隔内做出迁移决策。在每个epoch中,每个Load Monitor都会将观测到的元数据吞吐量发送给Migration Initiator(1)。当元数据集群的不平衡程度(由IF值表示)超过预定义阈值时,迁移启动器触发负载重新平衡过程,并生成迁移计划,将源MDS和目标MDS分配给MDS,并将目标MDS的需求和源MDS的能力配对。然后,每个源MDS上的Workload-aware Migration Planner将被通知其分配的迁移任务(2)。迁移任务到达后,子树选择器会选择一个合适的子树分区列表(3),然后将其输入到现有的Migrator中,并从负载较重的MDS迁移到负载较轻的MDSs(4)。
IF模型驱动的再平衡
采用变异系数(CoV)[20,46]作为我们模型的基本构建块。给定一个元数据集群,该集群由n服务器,其负载CoV值可以如下计算(标准差/平均值),li表示MDSi的当前负载,使用IOPS作为负载指标。
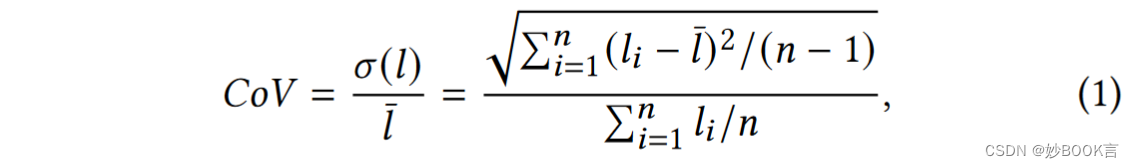
直接使用CoV有两个问题:
-
CoV的结果范围是不固定的 $ \left ( 0 , \sqrt{n}\right)$ ,因此将CoV标准化到(0, 1)
-
并非所有不平衡的情况都需要执行重新平衡过程,例如,尽管存在负载差异,但所有MDS都远低于其最大吞吐量。因此引入了一个紧迫性参数U,该值越高,就越迫切需要执行迁移。U计算如下:C表示单个MDS理论上可以实现的最大IOPS,S范围为(0, 1),这里设为0.2。
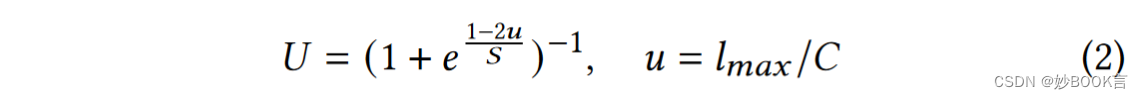
最终通过下式计算IF因子
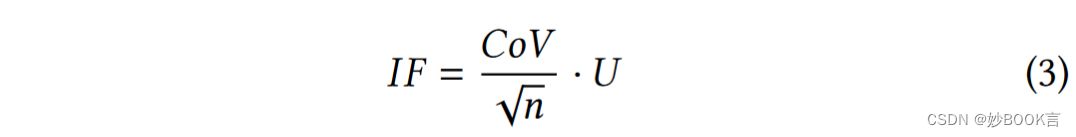
随后在迁移启动器应用上述模型来计算MDS集群在每个epoch中的IF值,如果负载不平衡程度超过预定义的阈值,则计算迁移角色和迁移量,如算法1所示,从每个MDS收集的负载统计信息,并计算矩阵E,其中Eij对应于需要从MDSi迁移到MDSj的负载数量。
-
考虑到迁移的开销,对MDS迁出/迁入设定了上限(𝑒𝑙𝑑 或𝑖𝑙𝑑),设置为在一个epoch内的最大容量(第8、12行)。该容量是一个常数值,可以计算为MDS理论上可以发送或接收的最大索引节点数。
-
进一步考虑未来负载变化的影响。对收集的历史负载统计数据(𝑐𝑙𝑑)应用线性回归模型,预测下一个epoch可能的负载(𝑓𝑙𝑑)。如果未来的负载增加无法满足缺口,则分配目标MDS角色,并计算其预期迁移负载量(第10-12行)。
-
考虑了源MDS和目标MDS的双向需求。对于源MDS和目标MDS对,检查源MDS是否有迁出需求,同时目标MDS是否需要迁入。如果是,使迁移量等于迁出和迁入的最小值,并减少迁移量。最后,该算法迭代运行,并在检查所有对时完成。
【几个需要预设的参数,S = 0.2、C、IF阈值 = 0.075、负载均衡阈值 L】

工作负载感知的子树选择
CephFS中的内置迁移策略依赖于运行时测量的文件元数据访问热度。但无法为各种场景提供良好的性能:(1)基于热度的解决方案忽略了空间局部性的影响;(2)尽管子树的热量可以累积和衰减,但无法对未来负载的方差进行建模。
提出方法:不维护子树的热计数器,而是为它们分配一个迁移索引(mIndex),该索引对应于目标子树随时间推移的预测未来负载。迁移指数越大,相应子树被迁移的概率就越高,从而消除无效但昂贵的迁移。
迁移指数需要联合考虑工作负载的时间局部性和空间局部性。引入𝛼和𝛽分别作为时间和空间局部性的影响因素,表明子树上最近的工作负载倾向于两种访问模式中的任何一种。为了估计这两个变量的值,在每个MDS上维护历史元数据访问跟踪,并将其分解为固定大小的短序列(也称为剪切窗口)。在子树基础上,定期计算𝛼为最近剪切窗口的重复访问率,该比率等于重复访问的索引节点数量除以总访问索引节点数量。定期计算𝛽为最近剪切窗口未访问率,该比率等于未访问的索引节点数量除以元数据访问总数。
预测未来访问次数lt和ls。通过最近 N 个剪切窗口中子树的元数据访问次数来计算 𝑙𝑡 的值。对于子树,如果其未访问的 inode 在当前剪切窗口中被访问,则将 𝑙𝑠 加1。还将以一定的概率选择其中一个兄弟子树,并将所选子树的 𝑙𝑠 值增加 1。
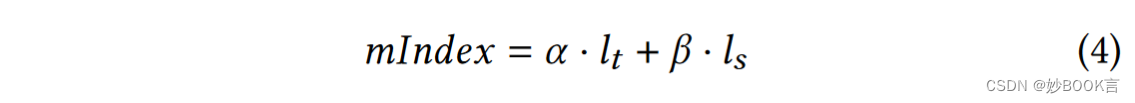
开销
开销较低。在每个epoch内,除了迁移启动器所在的主MDS之外,其他MDS的外部网络使用量增加了0.94 KB。在16-MDS集群中,主MDS在每个epoch仅产生14.1 KB的额外网络。此外,当将epoch时间设置为10秒时,每个MDS仅多消耗1.37%的内存空间来维护用于存储负载信息的数据结构。同时在启用Lunule时没有明显的CPU利用率差异。
实现细节
统计记录:用mIndex替代原本的计数器。每个inode都有一个长度为nlength的布尔队列,记录是否在最后n个epoch中访问。每当访问元数据时,其父目录都会检查队列并修改其𝑙𝑡或𝑙𝑠值。为了减少CPU开销,每个epoch仅更新一次,而不是在每次请求处理之后立即更新。
统计数据收集:为了减少大规模条件下的通信开销,采用中心化N-1负载监视器模块。在大多数情况下,将迁移启动器分配给级别最低的MDS,例如MDS-0。其它MDS首先将其状态发送给启动器,启动器在做出决定后与所有其他服务器进行通信。为此,在CephFS中引入了一种新的消息类型,即由MDS等级ID和元数据请求率组成的不平衡状态消息,以取代原始的心跳消息。
迁移触发和分配:启动器在收集集群统计数据后计算不平衡因子,并决定是否迁移。Lunule引入了另一种消息类型Migration Decision来调度决策。每个决策消息指定一个源MDS需要迁移到目标MDS的负载量。启动器将迁移负载消息发送给源MDS,在收到消息后继续下一步选择子树。
子树选择:使用简单的递归算法,通过以下三条搜索路径从根目录开始选择迁移子树:(1)确定是否有mIndex近似等于迁移的子树amount, 允许10%的差异;(2) 搜索mIndex大于迁移量的子树,并将其拆分为两个子树,其中一个子树的结果mIndex接近amount; (3) 选择一组小的子树,它们的mIndex值之和大致满足迁移需求。
实验环境
测试平台:实验在一个本地集群上运行,该集群有16个裸金属服务器,通过56Gb/s IPoIB网络连接。每台服务器有2个Intel(R)Xeon(R)E5-2650 V4 CPU、64 GB内存、1.6TB NVMe SSD(Intel P4610),运行CentOS 7.3.10.0862.14.4.el7.x86_64。
数据集:
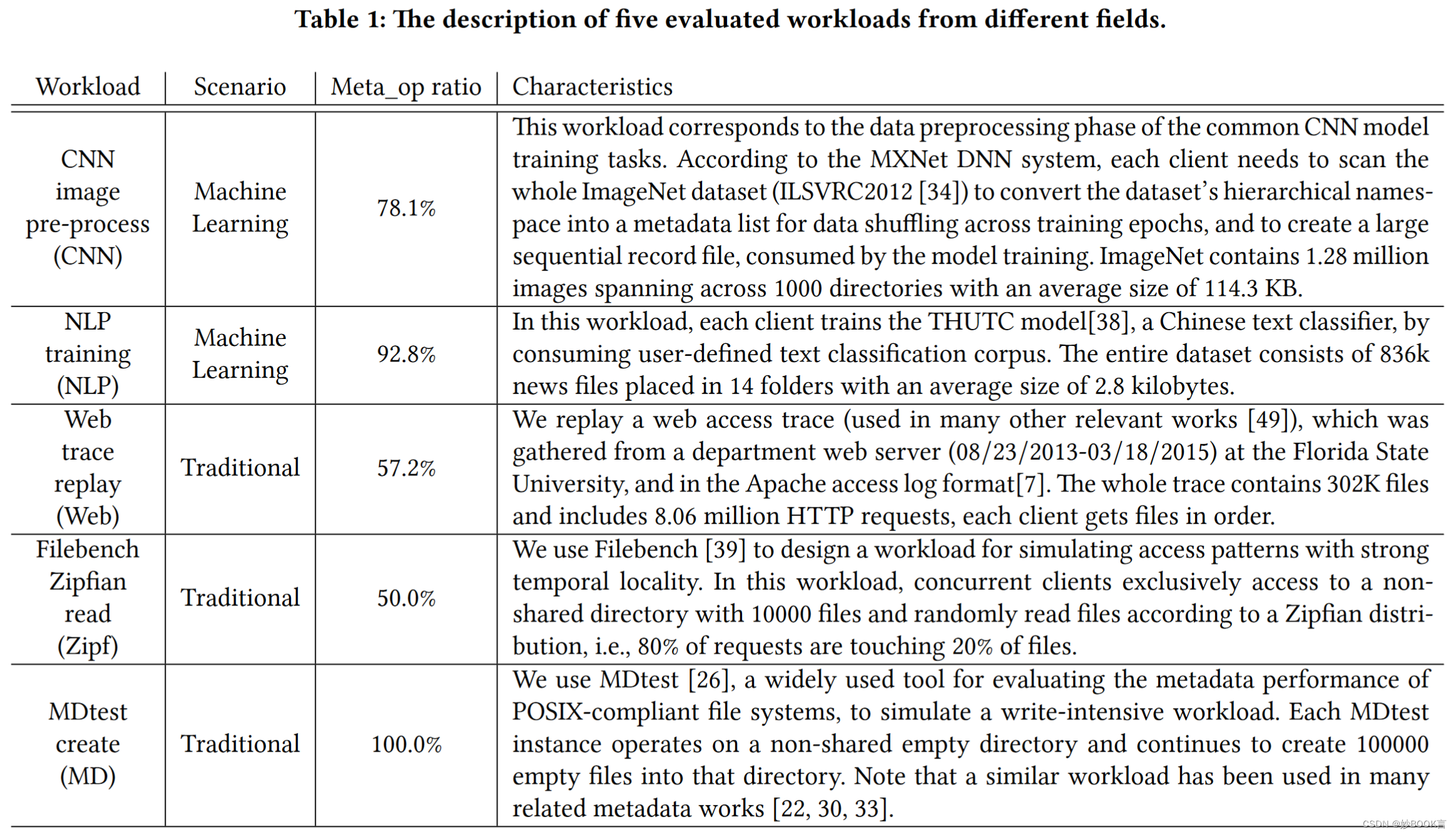
实验对比:负载不平衡情况、元数据吞吐量、作业完成时间
实验参数:数据集、混合负载、动态增加MDS和Workload
总结
对Ceph的元数据负载均衡机制进行优化,原始方法由于对未来负载预测的不准确和无效迁移导致性能低。作者通过变异系数计算不平衡因子模型,减小噪声影响,准确确定何时触发重新平衡;通过紧急参数,容忍良性的不平衡情况;感知工作负载时间局部性(最近时间间隔内元数据访问的重复性)和空间局部性(目标子树元数据访问的均匀分布,并考虑兄弟子树间的访问相关性),以选择子树迁移候选项。